
« Pouvez-vous citer trois moteurs de recherche ? », la question est posée et les sourcils se haussent. « Quelle est la différence entre un navigateur et un moteur de recherche ? », la perplexité peine à être dissimulée. « Comment ça marche un moteur de recherche ? » et le silence résonne. Au fil des ateliers d’éducation aux médias animés par Fragil, nous avons constaté que les personnes que nous encadrions, qu’elles soient élèves , étudiant·es, ados ou adultes, étaient très souvent perdues lorsqu’on évoquait avec elles l’un des outils qu’elles utilisent pourtant quotidiennement, à savoir les moteurs de recherche.
En faisant ce constat, nous avons décidé de développer un atelier permettant de vulgariser le fonctionnement technique des moteurs de recherche pour des groupes allant jusqu’à 30 personnes. Le voici détaillé ici.
Définir ce que sont les moteurs de recherche
En préambule, il est utile de sonder le groupe sur les noms d’entreprises qu’il associe aux moteurs de recherche. Commencer l’atelier par la question « Pouvez-vous citer trois moteurs de recherche ? » permet de mettre en lumière la confusion habituelle qui existe entre navigateurs web (Google Chrome, Mozilla Firefox, Safari…), logiciels qui permettent d’afficher des pages web sur son terminal (téléphone, ordinateur), et les moteurs de recherche (Google, Yahoo, Bing…) qui sont des sites affichant des listes de résultats de recherche associées à des requêtes spécifiques.

Une fois que le groupe a saisi la différence entre les deux notions, quitte à montrer un exemple sur un vidéo-projecteur, l’atelier pratique peut commencer.
Le matériel utilisé
Une trentaine de cartes représentant des pages web on été créées par Fragil (téléchargeable ici). Sur chacune de ces cartes, on peut retrouver :
– Une adresse web de type « 236.fr »
– Un titre
– Du contenu
– Des liens vers d’autres pages
– Un temps de chargement

Le vocabulaire
Indexation : l’indexation des documents consiste à associer des mots clés et informations à chaque document en fonction du plan de classement, afin de faciliter, ensuite, la recherche, l’accès et le traitement par les utilisateurs.
Robot d’indexation : un logiciel qui explore automatiquement le Web
Se transformer en robot d’indexation et remplir des bases de données
À l’aide de cartes créées spécialement pour l’occasion, représentant des pages web avec du contenu unique, les participants et participantes vont se mettre à la place des moteurs de recherche pour comprendre leur fonctionnement.
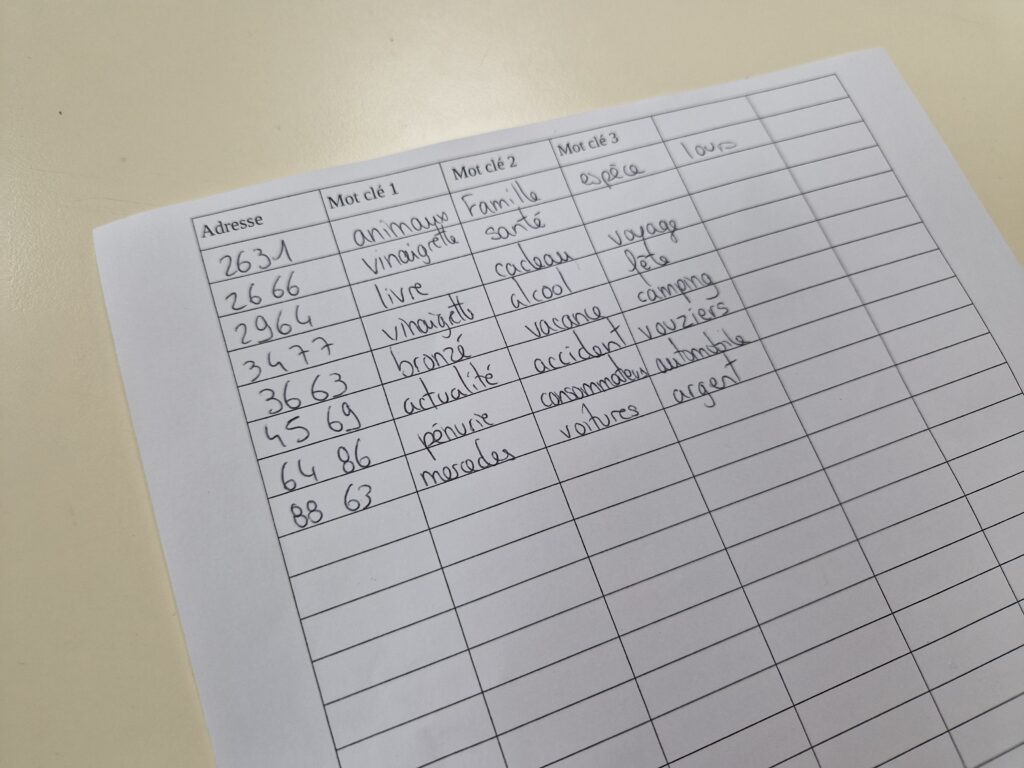
1/ On demande à 3 binômes de se porter volontaires : ce seront 3 moteurs de recherche différents. Chaque binôme choisit un nom (moteurderecherche.com, youpi.fr…) et définit les rôles des deux personnes : une sera « robot d’indexation » qui devra ramener des information issues de pages web à l’autre qui sera chargée d’inscrire ces information sur la « base de donnée » (un tableau vide imprimé sur une feuille)
2/ On distribue à chaque participant·e restant dans la pièce une ou deux cartes « page web » : ces personnes représenteront l’ensemble des pages existantes sur le web.
3/ Pendant 5 minutes, les équipes de « moteurs de recherche » vont indexer, de la manière la plus qualitative qui soit, le maximum de page web sur leur base de donnée, en suivant les deux règles suivantes :
-On ne peut traiter qu’une seule page à la fois
-Les robots ne peuvent consulter que des pages liées entre elles
A l’issue des 5 minutes, on débriefe rapidement et on compare le nombre de page indexées par chaque binôme.
Répondre à des requêtes
La personne en charge de l’animation va ensuite demander à chaque groupe de donner une liste classée des adresses de pages que chaque « moteur de recherche » recommande en fonction de requêtes précises. Ces résultats seront affichés au tableau pour que l’ensemble du groupe puisse observer les différences.
Les requêtes sont les suivantes :
– « Vinaigrette »
– « Beau chien »
– « Quelle est la meilleure équipe de foot ? »

A chaque affichage de résultat, on peut questionner le groupe en demandant « pourquoi chaque moteur de recherche donne des listes des résultats différentes ? ». Plusieurs pistes peuvent être évoquées pour expliquer ces différences. En cinq minutes, les robots n’auront pas eu le temps de parcourir « toutes » les pages du web, et n’auront permis qu’une indexation partielle. Les pages indexées ont été associées à des mots clés qui ne correspondent peut être pas tout à fait à la requête. Ou encore, les classements proposés par chaque binôme se sont basés sur des critères (algorithmes) différents : la page recommandée en premier était-elle la première page indexée sur le sujet de la requête ou bien était-ce une page comportant plus de mots clés en lien avec la requête ?
Questionner les limites des moteurs de recherche
« Je n’avais jamais réfléchi au fonctionnement des moteurs de recherche », « ça permet de comprendre qu’il y a des gens derrière », les retours à la suite de ce type d’atelier permettent de mettre en lumière le besoin d’explications du fonctionnement de certains outils utilisés quotidiennement par une grande partie de la population. En comprenant que les résultats de recherche de Google, Bing, ou encore Yahoo sont liés à la performance des robots d’indexation, à la qualité des données indexées et à l’algorithme de réponses aux requêtes, les participant·es peuvent s’interroger sur le pouvoir qu’ont ces moteurs de recherche en terme de trafic sur les sites web. Surtout lorsque ceux-ci, comme Google, sont en position de quasi monopole.
Que se passerait-il si Google décidait de ne plus indexer les pages sur lesquelles figurent le mot « chat » ?
Que se passerait-il si Google décidait de ne plus insérer dans ses résultats de recherche les pages sur lesquelles figurent le mot « censure » ?


